FinLab 函式庫
快速上手
FinLab 致力於推廣我們在量化投資上的知識與 Python 實作經驗,並且分享如何運用 Python 創造屬於自己的投資生態系,靠自己的能力為自己創造投資收入,不用在外花錢聽信無根據的明牌,讓大家用很低的成本複製我們在財經一路上的所學與經驗。除了過去在 Hahow 開設課程,現在為了打造更豐富的 Python 量化投資生態系,建置了 SaaS 與延伸教學內容平台,不斷研發,提供給大家更多武器應對複雜的金融市場。
會員註冊
進入首頁後,點選右上角登入按鈕,即可使用 Google 帳號登錄 FinLab 會員。若無 Google 帳號,請先 註冊 Google 帳號 方可接續進行。
快速安裝
提供3種選項,每個人都可以選擇適合自己的環境:
1. Python:
使用 pip install finlab 並且在一般 Python 環境下執行回測。
注意:若在finlab hahow課程資料夾內操作,可能與本地finlab模組有命名衝突問題,請重開新的python開發環境或在colab操作。
-
FinLab IDE: 免安裝,直接在網頁上執行 Python 程式語法,並搭配 FinLab 函式庫使用。
注意:免費權限有每日運行時間限制600秒,建議先在一般 Python 環境下執行回測(無限制時間),確認策略運作正常後,再將程式碼貼到FinLab IDE執行部屬。
-
FinLab GUI: 免安裝,直接在網頁上執行,用圖形化介面編輯策略。
Finlab IDE
#### Step1 左側導覽列點選選股策略Icon。 #### Step2 點選“建立新策略”。 #### Step3
輸入策略名稱,點選“確定”。
#### Step3
輸入策略名稱,點選“確定”。
 #### Step4:
點選“程式碼編輯器”,進入IDE開發畫面。
#### Step4:
點選“程式碼編輯器”,進入IDE開發畫面。

Finlab GUI
Step1:
左側導覽列點選選股策略Icon。Step2:
點選“建立新策略”。
Step3:
輸入策略名稱,點選“確定”。
Step4:
點選“圖形化編輯器”,進入GUI開發畫面。
獲取歷史資料
一行程式快速抓取豐富的股市資料庫!
Python
Step1:
利用 finlab.data 來得到「所有」歷史資料。 至[資料庫目錄](https://ai.finlab.tw/database)複製想獲取的資料的使用方法。 舉例:Step2:
初次下載資料會跳出驗證碼請求,若有成功註冊會員,畫面會顯示驗證碼,再將驗證碼複製填入“輸入驗證碼”欄位即可獲取資料。
Finlab IDE
方法1:
至[資料庫目錄](https://ai.finlab.tw/database)複製想獲取的資料的使用方法貼到IDE編寫。 舉例:方法2:
至IDE右側財務指標或技術指標點選,即可生成data.get(所選指標)的程式碼於IDE。 舉例:
Finlab GUI
Step1:
至IDE右側財務指標或技術指標點選,即可生成所選的指標拼圖於GUI。 舉例:
策略開發與回測
簡單開發策略,執行強大的回測系統!
Python
Step1:
利用python pandas及finlab語法撰寫條件程式碼。 [Colab範例檔連結。](https://colab.research.google.com/drive/1RVd2d6eW_A3yZGqLSl9PJ2LHGAoNIOOj?usp=sharing) 程式範例如下:from finlab import data
from finlab.backtest import sim
# 下載資料
pe = data.get('price_earning_ratio:本益比')
close = data.get('price:收盤價')
# 收盤價位於20日均線支撐上
cond1=close > close.rolling(20).mean()
# 使用indicator計算rsi指標
rsi=data.indicator('RSI', timeperiod=5)
# rsi高檔鈍化
cond2=(rsi>80).rolling(3).sum()==3
# 排除股價過高與過低的股票
cond3=(close > 5)&(close < 500)
# 選出買進訊號中益本比前10大標地
ind=(1/pe)*(cond1&cond2&cond3)
position=ind.is_largest(10)
sim(position,resample='M',name="demo_strategy")
Step2:
取得回測結果
Finlab IDE
Step1:
利用python pandas及finlab語法撰寫條件程式碼,範例如下:from finlab import data
from finlab.backtest import sim
# 下載資料
pe = data.get('price_earning_ratio:本益比')
close = data.get('price:收盤價')
# 收盤價位於20日均線支撐上
cond1=close > close.rolling(20).mean()
# 使用indicator計算rsi指標
rsi=data.indicator('RSI', timeperiod=5)
# rsi高檔鈍化
cond2=(rsi>80).rolling(3).sum()==3
# 排除股價過高與過低的股票
cond3=(close > 5)&(close < 500)
# 選出買進訊號中益本比前10大標地
ind=(1/pe)*(cond1&cond2&cond3)
position=ind.is_largest(10)
sim(position,resample='M',name="demo_strategy")
Step2:
執行程式(範例圖紅圈處)。
Step3:
取得回測結果。
Finlab GUI
Step1:
GUI操作原則: 1. 拼圖顏色由外而內配置順序為:紅、黃、藍、紫,不同顏色代表不同主功能。 1. 依資料邏輯填入數值,若邏輯正確,拼圖即可拼接,否則無法填入。 1. 拼接完成後,按下方執行鈕(範例圖紅圈處),回測即開始執行。 選股範例條件如下: 1. 收盤價位於20日均線支撐上。 1. rsi高檔鈍化,連3日大於80。 1. 股價介於5-500。 1. 最後選出買進訊號中益本比前10大標地。 GUI操作範例如下:
Step2:
取得回測結果。
模組功能指南
以下為使用 finlab package 更細部的介紹,針對每一個函式撰寫範例。
Finlab權限登入
finlab.login(api_token:str)
可以至
api_token查詢頁面 獲取api_token,執行finlab.login(api_token)登入來設置相關環境變數。
若不自行輸入,在使用Finlab模組執行會員功能時,系統會自動會跳出
GUI頁面 請求輸入api_token,驗證完方可使用對應權限的功能。
獲取歷史資料
finlab.data.get(dataset)
利用 finlab.data 來得到「所有」歷史資料,可以至資料庫目錄複製資料的使用方法。一行程式快速抓取豐富的股市資料庫! 目前針對 FREE 跟 VIP 用戶,所得到的資料時間段不同: * FREE 用戶:去除最近兩個月之歷史資料 * VIP 用戶:完整歷史和當天資料
資料格式為分為兩種:「時間序列資料」和「非時間序列資料」
1. 時間序列資料
資料獲取方法,就是使用 data.get 函式,傳入:主資料:子資料 的格式,例如price:收盤價。
獲得的資料,其縱軸為日期,橫軸為股票代號,製作選股策略非常方便。

2. 非時間序列資料(table)
資料獲取方法,就是使用 data.get 函式,傳入:主資料 的格式,例如 company_main_business。可以發現拿到的資料,不是按照時間序列排列。

技術指標計算
finlab.data.indicator(indname:str, adjust_price:bool=False, resample:str='D', **kwargs):
支援 Talib 和 pandas_ta 上百種技術指標!只需要一行,幫你算出2000檔股票、10年的所有資訊!
使用設定
在使用這個函式前,必需要先安裝 talib 套件,可以參考 官方安裝教學 來安裝,支援 Windows、MacOS、Linux。
參數說明:
indname: talib指標名稱,例如SMA,STOCH,RSI等,可以參考 talib 教學。adjust_price: 是否使用還原股價計算。resample: 技術指標價格週期,ex:D代表日線,W代表週線,M代表月線。**kwargs: 所選talib指標的其他參數設定,以RSI為例,參考 talib 文件中 RSI 範例,調整項為計算週期timeperiod。
建議使用者可以先參考以下範例,並且搭配 talib官方文件,就可以掌握製作技術指標的方法了。
範例一
計算所有股票的 RSI 數值

上圖中,可以看到資料包含 NaN ,代表資料筆數不足,無法計算出數值,每一檔股票除了剛開始的 14 天外,幾乎都會有數值。
範例二
計算所有股票的 KD 值,由於 KD 數值是由 K 和 D 所組成,每一檔股票每天會有兩個數值,所以 data.indicator 會自動回傳兩個 pd.DataFrame,可以用 k, d = data.indicator('STOCH') 將 K 與 D 數值紀錄,之後用於比大小,例如 k > d。

範例三 (續) 選股
延續上述的範例二,假如我們希望將最近一天 K > D 值的股票清單列出來,可以用以下語法
0015 False
0050 True
0051 False
0052 True
0053 True
...
9951 True
9955 False
9958 False
9960 True
9962 True
Name: 2021-07-13 00:00:00, Length: 2269, dtype: bool
範例四 - Pandas_ta 技術指標
finlab 0.3.2 dev1 版本開始支援 Pandas_ta 計算技術指標。 套件安裝方法及指標選項請見 Pandas_ta官方文件
我們將 Pandas_ta 與 Finlab 整合,使用方式非常的簡單,就跟以前一模一樣,用一行簡短的程式,就可以計算兩千檔股票的數值:
此時,程式會優先搜尋 TaLib 中是否有對應的函式,假如沒有的話,就會搜尋 Pandas_ta。可以讓你一次把所有股票的技術指標一次計算出來。缺點是 Pandas_ta 計算的速度比較慢,所以運算時要稍微等待一下。
限定上市櫃、類股
finlab.data.set_universe(market='ALL', category='ALL', exclude_category=None)
使用者可以使用此函式設定市場與類股的回測標的範圍。
設定完畢後,再使用 data.get 或是 data.indicator 時,就只會獲得所選範圍之標的,所得到的股票會被過濾。注意此設定影響為全域,若之後的data不想被影響,可使用以下程式。
參數說明
market (str): 市場名稱。 範例:'ALL', 'TSE', 'OTC', 'TSE_OTC', 'ETF'category (str or list): 類股名稱,可以使用模糊比對,例如'電子',會選到'電子工業','電子通路業'... 等;例如['水泥','鋼鐵'],會選到'水泥工業','鋼鐵工業'。exclude_category (str or list | None): 排除的類股名稱(支援模糊比對)。預設為None,例如:exclude_category='ETF'將排除所有 ETF 類別。
程式範例
限定只抓取上市櫃普通股(排除ETF、ETN、特別股、存託憑證)
from finlab import data
# 僅水泥工業,且排除 ETF
data.set_universe(market='TSE_OTC', category='水泥', exclude_category='ETF')
data.get('price:收盤價')

獲取已上傳策略的數據
finlab.data.get_strategies()
,可取得自己策略儀表板上的數據,像是每個策略的報酬率曲線、策略報酬率統計、近期部位、近期換股日等等,這些數據可以用來進行多策略彙整的應用喔!
參數說明
api_token (str): 預設為None,若未輸入過finlab模組的api_token,會自動跳出登入頁面。已登入的使用者不用再次輸入api_token參數。
返回值
{strategy1:{'positions':{},'returns':[],...},strategy2:{'positions':{},'returns':[],...},...}
回測模組
finlab.backtest.sim(position, resample=None, ...)
一行執行強大的回測系統,產生 position 的每日訊號,帶入 finlab.backtest.sim 進行回測,快速得到風險報酬分析、選股清單!
程式範例
你相信年報酬 +27% 的策略,程式碼三行就搞定嗎?讓 FinLab 打開你的眼界,接下來我們可以建構一個策略,策略每個月會檢查股票清單,持有價格小於 6 元的股票,剔除價格大於 6 元的股票,每個月底執行,周而復始。來回測看看這樣的績效到底如何:
from finlab import data
from finlab import backtest
# 只買入價格小於 6 元的股票
close = data.get('price:收盤價')
position = close < 6
# 回測,每月底(M)重新調整股票權重
backtest.sim(position, resample='M', name="價格小於6的股票")
參數說明
position (pd.Dataframe): 買賣訊號紀錄。 True 為持有, False 為空手。 若選擇做空position,只要將 sim(position) 改成負的sim(-position.astype(float))即可做空。 系統預設使用資料為台股與加密貨幣,若要使用美股或其他市場,將資料格式設定同為台股範例即可,index為datetime格式,column為文字格式的標的代號,注意每日自動更新服務不適用台股與加密貨幣的資料。 必填。resample (str): 交易週期。將position的訊號以週期性的方式論動股票,預設為每天換股。其他常用數值為W、M、Q(每週、每月、每季換股一次),也可以使用W-Fri在週五的時候產生新的股票清單,並且於下週交易日下單。更多freq的選擇請見pandas文件。trade_at_price (str): 選擇回測之還原股價以收盤價或開盤價計算,預設為'close'。可選'close'或'open'。fee_ratio (float): 交易手續費率,預設為台灣無打折手續費0.001425。可視個人使用的券商優惠調整費率。tax_ratio (float): 交易稅率,預設為台灣普通股一般交易交易稅率0.003。若交易策略的標的皆為ETF,記得設成0.001。-
name (str): 策略名稱,預設為未指名。策略名稱。相同名稱之策略上傳會覆寫。命名規則:全英文或開頭中文,不接受開頭英文接中文。 *
stop_loss (float): 停損基準,預設為None,不執行停損。範例:0.1,代表成本價虧損 10% 時出場。 *take_profit (float): 停利基準,預設為None,不執行停利。範例:0.1,代表成本價獲利 10% 時出場。 *position_limit(float): 單檔標的持股比例上限,控制倉位風險。預設為None。範例:0.2,代表單檔標的最多持有 20 % 部位。 *touched_exit(bool): 觸及到賣出訊號即以訊號日當下出場。預設為False,訊號產生後隔日出場。 *mae_mfe_window(int): 計算mae_mfe於進場後於不同持有天數下的數據變化,主要應用為edge_ratio (優勢比率)計算。預設為0,則Report.display_mae_mfe_analysis(...)中的edge_ratio不會顯現。 *mae_mfe_window_step(int): 與mae_mfe_window參數做搭配,為時間間隔設定,預設為1。若mae_mfe_window設20,mae_mfe_window_step設定為2,相當於python的range(0,20,2),以2日為間距計算mae_mfe。 *upload(bool): 上傳策略至finlab網站,預設為True,上傳策略。範例: False,不上傳,可用finlab.backtest.sim(position, upload=False, ...).display()快速檢視策略績效。
返回值
finlab.report.Report()

此時,使用者可以點選下方的「選股清單」來查看今天的持股狀況,甚至是手動跟單,來將虛擬的獲利變成現實。

多空並存回測
若策略想同時做多和做空,可參考以下範例,範例是做多 2330 一半的部位,做空 1101 一半的部位。
from finlab import data
from finlab import backtest
close = data.get('price:收盤價')
position = close < 0
position['2330'] = 0.5
position['1101'] = -0.5
r = backtest.sim(position)
r.display()
Report物件
class finlab.report.Report()
產生策略分析報告。
屬性:
Report.position: 得到每日歷史部位明細 (pd.Dataframe)。
Report.creturn: 得到策略報酬率變化 (pd.Series)。
Report.benchmark: 設定對標標準 (pd.Series)。預設為None,台股對標台股加權報酬指數,加密貨幣對標BTC/USD走勢。若要改為對標0050或其他標的,範例如下。
from finlab import data,backtest
pb = data.get('price_earning_ratio:股價淨值比')
close = data.get('price:收盤價')
position=(1/(pb * close) * (close > close.average(60)) * (close > 5)).is_largest(20)
rr=backtest.sim(position=-position.astype(float),resample='Q',upload=False)
rr.benchmark = close['0050']
rr.display()
方法:
Report.display():
顯示策略績效圖。

Report.get_stats():
取得策略統計數據,如夏普率、索提諾比率、最大回檔、近期報酬率統計。
Report.get_trades(): 取得策略每筆交易紀錄資料。
-
返回值
trade_record: pd.Dataframe ##### trade_record 重點欄位說明- exit_sig_date:進場訊號產生日。
- entry_sig_date:出場訊號產生日。
- entry_date:進場日。
- exit_date:出場日。
- return:報酬率。
- mdd:持有期間最大回撤。
- mae:持有期間最大不利報酬率幅度。
- gmfe:持有期間最大有利報酬率幅度。
- bmfe:mae發生前的最大有利報酬率幅度。
- position: 持有佔比。
- period:持有天數。
- pdays:處於獲利時的天數。
Report.display_mae_mfe_analysis(...): 顯示波動分析圖組。
分析使用說明。
-
參數說明
atr_freq(int): edge_ratio使用的 ATR 時段週期參數。預設為10。violinmode(str): violin型態統計圖樣式,模式分為'group'與'overlay'。預設為'group','group'模式為將交易勝敗手分群統計呈現','overlay'採取全數統計。
返回值
figure(obj)
程式範例
from finlab import data
from finlab.backtest import sim
pb = data.get('price_earning_ratio:股價淨值比')
close = data.get('price:收盤價')
position = (1/(pb * close) * (close > close.average(60)) * (close > 5)).is_largest(20)
report = sim(position, resample='Q',mae_mfe_window=30,mae_mfe_window_step=2)
report.position
report.creturn
report.benchmark = data.get('benchmark_return:發行量加權股價報酬指數').squeeze()
report.display()
report.get_trades()
#report.display_mae_mfe_analysis()
回測語法糖
class finlab.dataframe.FinlabDataFrame()
除了使用熟悉的 Pandas 語法外,我們也提供很多語法糖,讓大家開發程式時,可以用簡易的語法完成複雜的功能,讓開發策略更簡潔!我們將所有的語法糖包裹在 FinlabDataFrame 中,用起來跟 pd.DataFrame 一樣,但是多了很多功能!只要使用 finlab.data.get() 所獲得的資料,皆為 FinlabDataFrame 格式,接下來我們就來看看, FinlabDataFrame 有哪些好用的語法糖吧!
日月季不等式、四則運算
當資料日期沒有對齊(例如: 財報 vs 收盤價 vs 月報)時,在使用以下運算符號:+, -, *, /, >, >=, ==, <, <=, &, |, ~,不需要先將資料對齊,因為 FinlabDataFrame 會自動幫你處理,以下是示意圖。

以下是範例:cond1 與 cond2 分別為「每天」,和「每季」的資料,假如要取交集的時間,可以用以下語法:
from finlab import data
# 取得 FinlabDataFrame
close = data.get('price:收盤價')
roa = data.get('fundamental_features:ROA稅後息前')
# 運算兩個選股條件交集
cond1 = close > 37
cond2 = roa > 0
cond_1_2 = cond1 & cond2
擷取 1101 台泥 的訊號如下圖,可以看到 cond1 跟 cond2 訊號的頻率雖然不相同,但是由於 cond1 跟 cond2 是 FinlabDataFrame,所以可以直接取交集,而不用處理資料頻率對齊的問題。

均線
FinlabDataFrame.average(n)
取 n 筆移動平均,若股票在時間窗格內,有 N/2 筆 NaN,則會產生 NaN。
範例:股價在均線之上
只需要簡單的語法,就可以將其中一部分的訊號繪製出來檢查:import matplotlib.pyplot as plt
close.loc['2021', '2330'].plot()
sma.loc['2021', '2330'].plot()
cond.loc['2021', '2330'].mul(20).add(500).plot()
plt.legend(['close', 'sma', 'cond'])

每列數值最大的 n 檔股票
FinlabDataFrame.is_largest(n)
取每列前 n 筆大的數值,若符合 True ,反之為 False 。用來篩選每天數值最大的股票

選股範例:每季 ROA 前 10 名的股票
from finlab import data
roa = data.get('fundamental_features:ROA稅後息前')
good_stocks = roa.is_largest(10)
每列數值最小的 n 檔股票
FinlabDataFrame.is_smallest(n)
取每列前 n 筆小的數值,若符合 True ,反之為 False 。用來篩選每天數值最小的股票
範例:股價淨值比最小的 10 檔股票
from finlab import data
pb = data.get('price_earning_ratio:股價淨值比')
cheap_stocks = pb.is_smallest(10)
訊號進出場
entries.hold_until(exits, ...)
這大概是所有策略撰寫中,最重要的語法糖,上述語法中 entries 為進場訊號,而 exits 是出場訊號。所以 entries.hold_until(exits) ,就是進場訊號為 True 時,買入並持有該檔股票,直到出場訊號為 True 則賣出。

此函式有很多細部設定,可以讓你最多選擇 N 檔股票做輪動。另外,當超過 N 檔進場訊號發生,也可以按照客制化的排序,選擇優先選入的股票。最後,可以持外設定停損停利,來增加出場的時機點。以下是 hold_until 的參數說明:
exit (pd.Dataframe): 出場訊號。nstocks_limit (int): 輪動檔數上限,預設為None。stop_loss (float): 停損基準,預設為None,不執行停損。範例:0.1,代表成本價下跌 10% 時產生出場訊號。take_profit (float): 停利基準,預設為None,不執行停利。範例:0.1,代表成本價上漲 10% 時產生出場訊號。trade_at (str): 停損停利參考價,預設為'close'。可選close或open。rank (pd.Dataframe): 當天進場訊號數量超過 nstocks_limit 時,以 rank 數值越大的股票優先進場。
Note
若要使用 hold_until 與停損停利,將停損停利設置在 hold_until 內即可,不可將停損停利設置在finlab.backtest.sim,以避免衝突。
策略範例
價格 > 20 日均線入場, 價格 < 60 日均線出場,最多持有10檔,超過 10 個進場訊號,則以股價淨值比小的股票優先選入。
from finlab import data
from finlab.backtest import sim
close = data.get('price:收盤價')
pb = data.get('price_earning_ratio:股價淨值比')
sma20 = close.average(20)
sma60 = close.average(60)
entries = close > sma20
exits = close < sma60
#pb前10小的標的做輪動
position = entries.hold_until(exits, nstocks_limit=10, rank=-pb)
sim(position)
數值上升中
rise(n=1)
取是否比前第n筆高,若符合條件的值則為True,反之為False。

程式範例:收盤價是否高於10日前股價
數值下降中
fall(n=1)
取是否比前第n筆低,若符合條件的值則為True,反之為False。
程式範例:收盤價是否低於10日前股價
持續 N 天滿足條件
FinlabDataFrame.sustain(nwindow, nsatisfy=None)
取移動 nwindow 筆加總大於等於nsatisfy,若符合條件的值則為True,反之為False。
程式範例:收盤價是否連兩日上漲
股票當天數值分位數
FinlabDataFrame.quantile_row(n=1)
取得每列n定分位數的值。
程式範例:取每日股價前90%分位數
財務月季報索引格式轉換
FinlabDataFrame.index_str_to_date()
將以下資料的索引:月營收 (ex:2022M01) ,財務季報 (ex:2022Q1) 從文字格式轉為公告截止日的datetime格式,通常使用情境為對不同週期的dataframe做reindex,常用於以公告截止日為訊號產生日的時候。
程式範例:
from finlab import data
data.get('monthly_revenue:當月營收').index_str_to_date()
data.get('financial_statement:現金及約當現金').index_str_to_date()
產業分群
FinlabDataFrame.groupby_category()
資料按產業分群,類似 pd.DataFrame.groupby()。
程式範例:半導體平均股價淨值比時間序列
from finlab import data
pe = data.get('price_earning_ratio:股價淨值比')
pe.groupby_category().mean()['半導體'].plot()

全球 2020 量化寬鬆加上晶片短缺,使得半導體股價淨值比衝高。
進場點
FinlabDataFrame.is_entry()
取進場訊號點,若符合條件的值則為True,反之為False。
程式範例:策略為每日收盤價前10高,取進場點。
出場點
FinlabDataFrame.is_exit()
取出場訊號點,若符合條件的值則為 True,反之為 False。
程式範例:策略為每日收盤價前10高,取出場點。
回測條件範例
創新高策略
股票最忌諱就是「買高賣低」,汲汲營營,但是你有沒有想過,大家都怕買高,反而要買更高?
創新高的股票,由於受到市場的關注,上漲動能非常強,所以選擇這些股票,就能帶來不錯的報酬率。
下方的條件,使用了 pd.DataFrame 裡的功能 rolling(250).max(),代表 250 天的最高價,
假如今天的收盤,等於 250 天的最高價,就代表創新高了!
from finlab import data
from finlab.backtest import sim
# 創 250 天新高的股票
close = data.get('price:收盤價')
position = (close == close.rolling(250).max())
# 回測,每月(M)調整一次,選出當天創新高股票
sim(position, resample='M', name="創年新高策略")

高 RSI 技術指標策略
上述策略會選出很多檔標的,要是我們只想要選出 20 檔要怎麼寫呢?這個策略我們可以將 RSI 最大的 20 檔股票納入組合,並且持有一週,來試試看效果如何。我們可以用 data.indicator 來計算所有股票的 RSI,也可以用 rsi.is_largest 來計算此股票的 RSI 是否是最大的 20 檔。
from finlab import data
from finlab.backtest import sim
# 選出 RSI 最大的 20 檔股票
rsi = data.indicator('RSI')
position = rsi.is_largest(20)
# 回測,每月(M)調整一次
report = sim(position, resample='W', name="高RSI策略")

乖離率和財報濾網策略
可以一次使用兩種不同的指標來選股嗎?答案是肯定的,而且這兩個指標,還可以是每季的財報跟每天的價格,混和條件選股,由於下方的 roe 和 close 並不是 pd.DataFrame 而是 finlab.dataframe.FinlabDataFrame ,當在做條件運算,例如交集、聯集(and or)時,不同頻率的 index 會被取連集並且整合,所以使用者不需要思考,究竟資料是「季」還是「月」還是「日」,可以直接當作 index 和 columns 是對齊的,直接運算(程式會自動想辦法)。
下面的策略,利用 close / close.shift(60) 計算乖離率,並取 30 檔股票出來,再用 ROE 當濾網,選擇 ROE 為正的股票。
from finlab import data
from finlab.backtest import sim
# 下載 ROE 跟收盤價
roe = data.get("fundamental_features:ROE稅後")
close = data.get('price:收盤價')
position = (
(close / close.shift(60)).is_largest(30) # 選出乖離率前 30 名的股票
& (roe > 0) # 選出 ROE 大於 0 的股票
)
# 回測,每月(M)調整一次
report = sim(position, resample='M', name="乖離率和ROE濾網策略")

下單串接
執行交易策略
目前交易系統僅支援 finlab>=0.3.0.dev1 版本。在下單前,請先確認安裝了新版的 Package 喔!
首先,在下一個交易日開盤前,執行策略:
計算股票張數
接下來,顯示最近的部位
| entry_date | exit_date | entry_sig_date | exit_sig_date | position | period | entry_index | exit_index | return | entry_price | exit_price | mae | gmfe | bmfe | mdd | pdays | weight | next_weights | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| stock_id | ||||||||||||||||||
| 1416 廣豐 | 2021-10-01 | NaT | 2021-09-30 | 2022-06-30 | 0.510197 | 159.0 | 3566.0 | -1.0 | -3.539823e-02 | 10.60 | NaN | -0.053097 | 0.070796 | 0.070796 | -0.115702 | 37.0 | 0.060665 | 0.00 |
| 1453 大將 | 2021-10-01 | NaT | 2021-09-30 | 2022-06-30 | 0.510197 | 159.0 | 3566.0 | -1.0 | 2.348165e+00 | 8.43 | NaN | -0.086763 | 2.403782 | 0.245829 | -0.624585 | 60.0 | 0.171264 | 0.00 |
| 1524 耿鼎 | 2022-04-01 | NaT | 2022-03-31 | 2022-06-30 | 0.611632 | 39.0 | 3686.0 | -1.0 | -3.330669e-16 | 10.60 | NaN | -0.476658 | 0.015152 | 0.000000 | -0.476658 | 2.0 | 0.122168 | 0.00 |
| 2543 皇昌 | 2021-10-01 | NaT | 2021-09-30 | NaT | 0.510197 | 159.0 | 3566.0 | -1.0 | 1.073232e-01 | 7.46 | NaN | -0.063131 | 0.363636 | 0.008838 | -0.268519 | 44.0 | 0.070298 | 0.05 |
| 2701 萬企 | 2022-04-01 | NaT | 2022-03-31 | 2022-06-30 | 0.611632 | 39.0 | 3686.0 | -1.0 | -3.330669e-16 | 12.05 | NaN | -0.025105 | 0.029289 | 0.029289 | -0.052846 | 18.0 | 0.063107 | 0.00 |
假如確認沒問題,可以計算每檔股票投資的張數:
from finlab.online.order_executor import Position
# total fund
fund = 1000000
position = Position.from_report(report, fund)
print(position)
[{'stock_id': '2330', 'quantity': 1, 'order_condition':
上述 Position 代表您的帳戶中,只希望有一張 2330 台積電股票,並且是現貨。
部位增減調整
我們可以用以下方法調整部位大小
# 減一張 2330 股票
new_position = position - Position({'2330': 1})
# 增加一張 1101 股票
new_position = position + Position({'1101': 1})
多策略權重加總
假如我們有多個 position,可以用以下方式加總:
from finlab import backtest
from finlab.online.order_executor import Position
report1 = backtest.sim(...)
report2 = backtest.sim(...)
position1 = Position.from_report(report1, 1000000) # 策略操作金額一百萬
position2 = Position.from_report(report2, 1000000) # 策略操作金額一百萬
total_position = position1 + position2
實際下單
1 安裝券商 API
目前支援 玉山 Fugle 和 永豐 證券的下單系統,則一使用即可。
2 連接證券帳戶
目前支援 Fugle 和 永豐 證券的下單系統,可以先將帳號密碼設定成環境變數,只要針對您需要的券商來設定即可,不需要兩個券商同時串接。
2.1 玉山富果 帳戶串接
請先按照config 教學獲取 config 設定檔。 並到登入富果API,獲得市場行情 Token。
from finlab.online.fugle_account import FugleAccount
import os
os.environ['FUGLE_CONFIG_PATH'] = '玉山富果交易設定檔(config.ini.example)路徑'
os.environ['FUGLE_MARKET_API_KEY'] = '玉山富果的行情API Token'
acc = FugleAccount()
2.2 永豐帳戶串接
請先獲取憑證
import os
from finlab.online.sinopac_account import SinopacAccount
os.environ['SHIOAJI_ACCOUNT']= '永豐證券帳號'
os.environ['SHIOAJI_PASSWORD']= '永豐證券密碼'
os.environ['SHIOAJI_CERT_PATH']= '永豐證券憑證路徑'
acc = SinopacAccount()
3 批次下單
最後利用 OrderExecuter 將當證券帳戶的部位,按照 position 的部位進行調整。
from finlab.online.order_executor import OrderExecutor
# Order Executer
order_executer = OrderExecutor(position , account=acc)
# 下單檢查(瀏覽模式,不會真的下單)
order_executer.create_orders(view_only=True)
# 執行下單(會真的下單,初次使用建議收市時測試)
# 預設使用最近一筆成交價當成限價
order_executer.create_orders()
# 更新限價(將最後一筆成交價當成新的限價)
order_executer.update_order_price()
# 刪除所有委託單
order_executer.cancel_orders()
策略管理介面
刪除策略
點選策略右側齒輪符號(下圖紅圈處)刪除策略。

設定自動更新策略
點選右上“設定自動更新策略”按鈕,設定需要每日自動更新清單與回測的策略,選取策略名稱與更新時間,目前每個帳號限定3項策略可自動更新。
Note:限定使用Finlab IDE介面上傳程式後,方可設定“自動更新策略”。使用colab或其他編輯器者,可在撰寫完策略後,將程式貼於Finlab IDE介面執行。

分享策略
Step1: 點選策略名稱進入策略,之後點選在策略名稱旁的齒輪符號。

Step2: 進入“策略網址的分享權限設定,未設定公開前,只有帳戶本人才能看到自己的策略。若想分享策略清單與相關程式,權限可以選擇“隱藏”之外的選項。

Step3: 確認設定後,即可分享策略的網址給其他人參考。

視覺化子模組(暫不支援網頁)
K線圖組
finlab.plot.plot_tw_stock_candles(stock_id, recent_days=400, ...)
繪製K線圖,可以各種技術指標跟 K 線圖一起繪製。
參數說明
stock_id (str): 必填,標地代碼 ex:2330。recent_days (int): 取近n日內的資料,預設為400。adjust_price (bool): 是否使用還原股價,預設為False。resample (str): 技術指標價格週期,預設為'D',範例:D代表日線,W代表週線,M代表月線。overlay_func (dict): 主圖輔助線,預設為None,顯示布林通道。範例可以參考下方教學 自定義格式寫法如下:technical_func(dict or dict in list): 技術指標子圖,預設為None,顯示KD指標。 自定義格式寫法如下:technical_func 為dict in list格式,可任意設定技術指標組數,像是範例會產生兩組技術指標圖:from talib import abstract { 'rsi_10':lambda df:abstract.RSI(df['close'],timeperiod=10), 'rsi_20':lambda df:abstract.RSI(df['close'],timeperiod=20), }from talib import abstract technical_func = [ { 'rsi_10': lambda df: abstract.RSI(df['close'], timeperiod=10), 'rsi_20': lambda df: abstract.RSI(df['close'], timeperiod=20), }, { 'K': lambda df: abstract.STOCH(df['high'],df['low'],df['close'])[0], 'D': lambda df: abstract.STOCH(df['high'],df['low'],df['close'])[1], } ]
圖例
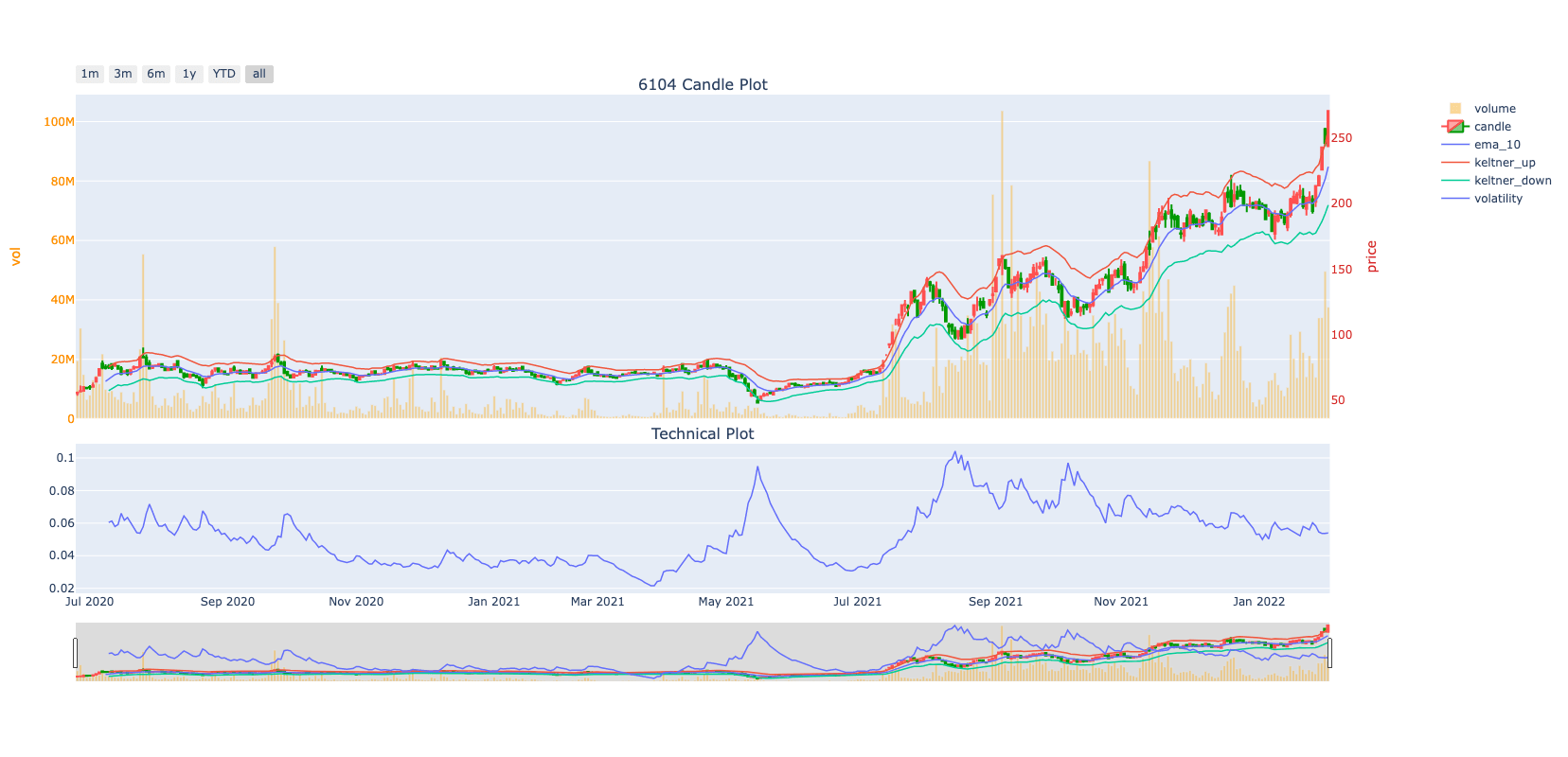
範例一:單一股票繪圖
最簡單的範例如下,可以直接呼叫並且繪製 2330 台積電的股價
範例二:日、月線繪圖
範例三:客制化技術指標繪圖
我們可以額外使用 talib 來繪製想要看的技術指標,例如 5日、10日、20日的移動幾何平均,由於這些技術指標,是跟股價繪製在一起,所以可以用 overlay_function 這個參數。
from finlab.plot import plot_tw_stock_candles
from talib import abstract
overlay_func = {
'ema_05': lambda df: abstract.EMA(df.close, timeperiod=5),
'ema_10': lambda df: abstract.EMA(df.close, timeperiod=10),
'ema_20': lambda df: abstract.EMA(df.close, timeperiod=20),
}
plot_tw_stock_candles("2330", overlay_func=overlay_func)
範例四:客制化技術指標繪圖
與上述的範例不同,技術指標如 KD、RSI,不能跟股價繪製在同一張圖表,需要額外在不同的圖表上繪製,就可以使用 technical_func 來繪製,technical_func 為dict in list格式,可任意設定技術指標組數,像是範例會產生兩組技術指標圖:
from finlab.plot import plot_tw_stock_candles
from talib import abstract
technical_func = [
{
'rsi_10': lambda df: abstract.RSI(df['close'], timeperiod=10),
'rsi_20': lambda df: abstract.RSI(df['close'], timeperiod=20),
},
{
'K': lambda df: abstract.STOCH(df['high'],df['low'],df['close'])[0],
'D': lambda df: abstract.STOCH(df['high'],df['low'],df['close'])[1],
}
]
plot_tw_stock_candles("2330", technical_func=technical_func)
樹狀板塊地圖
finlab.plot.plot_tw_stock_treemap(start, end, ...)
板塊地圖,可以用來瞭解股票的成交量分佈,以及現金流的轉換。
參數說明
start (str): 必填,資料起始日,ex:2021-01-02。end (str): 必填, 資料結束日,ex:2021-01-05。adjust_price (bool): 是否使用還原股價,預設為False。area_ind (str): 決定板塊面積大小的參數,預設為'market_value',可選範圍為["market_value", "turnover", "turnover_ratio"](分別為:市值、交易力量、交易佔比)。item (str): 決定板塊面積大小的參數,預設為'return_ratio',預設可選範圍為["return_ratio", "turnover_ratio"]或是帶入finlab database的使用方法,ex:'price_earning_ratio:本益比'。-
color_scales (str): 色溫條樣式,預設為'Temps'。 樣式選擇詳細資訊。 -
clip (tuple): 數值限定範圍,預設為None。避免數值範圍過大讓色溫顯示過淡,ex:(0,100)。
程式範例
以下範例為使用此函式,繪製出 2021-7-1 ~ 2021-7-2 的成交量的比例。其面積是成交量的大小,而顏色則是上漲或下跌的幅度。
from finlab.plot import plot_tw_stock_treemap
plot_tw_stock_treemap(
start='2021-7-1',
end='2021-7-2',
area_ind='turnover_ratio',
item='turnover_ratio')

PE、PB 河流圖
finlab.plot.plot_tw_stock_river(start=None, end=None, stock_id='2330', mode='pe', split_range=8)
河流圖,可以用來瞭解股票指標的歷史位階。
參數說明
start (str): 資料起始日,預設為None,帶入全部資料。ex:'2021-01-02'。end (str): 資料結束日,預設為None,帶入全部資料。ex:'2021-01-05'。stock_id (str): 股號,預設為'2330',ex:'2330'。mode (str): 資料模式,預設為'pe',可選範圍為["pe", "pb"],分別為本益比、股價淨值比。split_range (int): 河流階層數,預設為8層。
程式範例
以下範例為使用此函式繪製出台積電的歷史本益比河流圖。
from finlab.plot import plot_tw_stock_river
plot_tw_stock_river(stock_id='2330',mode='pb',split_range=8)

財務指標分級雷達圖
finlab.plot.plot_tw_stock_radar(df=None, feats=None, ...)
參數說明
-
df(dataframe): 客製化指標dataframe,數值使用pandas的rank與cut做群組分級。如果不填,則使用下一個feats參數帶入現有資料庫指標 格式範例: -
feats (list): 指標清單,填入資料庫使用方法至list。預設為20項常用財務指標。 格式範例: select_targets(list): 必填,台股標的清單。 格式範例:['1101','1102']mode(str): 雷達圖模式選擇,預設為'line_polar',可用模式為'line_polar','bar_polar','scatter_polar', 詳細資訊。line_polar_fill(str): line_polar模式下的圖型填滿選擇,預設為'None',可用模式為:None,'toself','tonext', 詳細資訊。cut_bins(int): 設定指標分級級距,預設為10。title(str): 設定圖表標題,預設為None。
範例一 Polar Bar
適合呈現整體投資組合指標累積評分結果。
from finlab.plot import plot_tw_stock_radar
plot_tw_stock_radar(
select_targets=["1101", "2330", "8942", "6263"],
mode="bar_polar" ,
line_polar_fill=line_polar_fill)

範例二 Polar Line
line_polar 適合比較單一標地指標評分。
from finlab.plot import plot_tw_stock_radar
plot_tw_stock_radar(
select_targets=["1101", "2330", "8942", "6263"],
mode="bar_polar" ,
line_polar_fill=None)

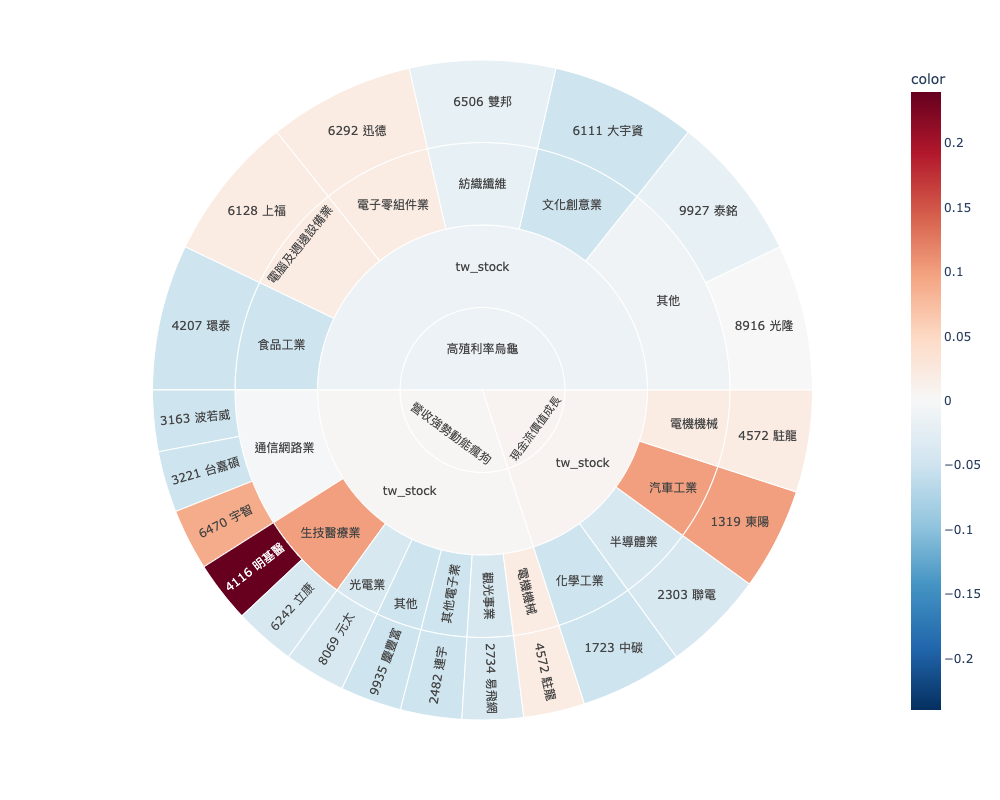
多策略資產配置旭日圖
finlab.plot.StrategySunburst().plot(select_strategy=None, path=None, color_continuous_scale='RdBu_r')
多策略旭日圖 (sunburst),可以用來瞭解已部署的策略,檢視當前的持股部位與配置資訊。
參數說明
select_strategy (dict): 設定選取的策略與策略對應的持股現值權重,預設是策略全選,權重為策略數的平均值。也可以自訂匡選的策略,像是只想看兩個實戰的策略,並分別設定6成與4成持股現值比重,可以設定成 {'低波動本益成長比':0.6,'研發魔人':0.4} 。若有現金的空部位想加入資產配置,可以設定成 {'低波動本益成長比':0.5,'研發魔人':0.2, '現金':0.2} ,策略名稱為現金,即可創造現金部位。path (list): sunburst 分層路徑,預設由裡到外的分層是 ['s_name', 'market', 'category', 'stock_id'] ,可以觀察策略持有哪些類股為主。你可以自動設定分層,會有不同的效果,像是也可以設成 ['category','stock_id','s_name'] 變成可以看標的被哪些策略同時選到。color_continuous_scale (str): color_continuous_scale (str):預設為'RdBu_r',可以自選其他樣式。
程式範例
from finlab.plot import StrategySunburst
# 實例化物件
strategies = StrategySunburst()
s_data = strategies.s_data
print(f'已上傳的策略名稱:{s_data.keys()}')
# 範例1
strategies.plot().show()
# 範例2
strategies.plot(select_strategy={'高殖利率烏龜':0.5,'營收強勢動能瘋狗':0.3,'現金流價值成長':0.2}).show()
# 範例3
strategies.plot(select_strategy={'高殖利率烏龜':0.4,'營收強勢動能瘋狗':0.25,'現金流價值成長':0.2,'現金':0.15},path = ['market', 'category','stock_id','s_name']).show()
Pandas 常用語法
FinLab 策略程式的開發建立在 Pandas 的基礎,藉由 Pandas 強大的資料處理功能,我們可以省下許多學習成本,更方便地操控資料。以下整理出經常使用在策略撰寫函數,並以 Finlab 財經資料為範例,示範策略轉寫。若你已經有 Python 基礎,此份資料方便你在處理資料遇到困難時得以檢索、複習、套用,無論在使用 Finlab 模組功能或開發其他延伸應用,都能得心應手。若你想操考更多語法功能細節,請參考文章底處的參考資源連結。
讀取函式庫
準備歷史資料
pd.Dataframe 建立二維資料表,有索引與欄位。可想成是多欄資料,由多個Series組成。
資料格式範例,我們這個章節,將分析三檔股票
* 鴻海 2317
* 台積電 2330
* 大立光 3008
利用語法將 2018 年的股票資料取出,接下來的資料分析,就會著重在這三檔股票。
2317 2330 3008
date
2018-01-02 95.0 232.5 4255.0
2018-01-03 94.0 237.0 4145.0
2018-01-04 92.6 239.5 4135.0
2018-01-05 93.0 240.0 4100.0
2018-01-08 91.8 242.0 3930.0
... ... ... ...
2018-12-24 71.4 220.0 3270.0
2018-12-25 70.7 217.5 3165.0
2018-12-26 70.2 216.5 3125.0
2018-12-27 70.8 223.0 3135.0
2018-12-28 70.8 225.5 3215.0
資料檢索
可以將上述的 df 中,用時間和股票來選取其中的一小部分,以下是各種的用法:
-
選取「列」
我們可以選取歷史資料中的一條時間序列,例如我們希望將
2330台積電從上述df中取出來: -
選取頭跟尾
head & tail 會選取前 n 筆,和後 n 筆資料,預設
n = 5 -
選取 index 跟 columns
DatetimeIndex(['2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-08', '2018-01-09', '2018-01-10', '2018-01-11', '2018-01-12', '2018-01-15', ... '2018-12-18', '2018-12-19', '2018-12-20', '2018-12-21', '2018-12-22', '2018-12-24', '2018-12-25', '2018-12-26', '2018-12-27', '2018-12-28'], dtype='datetime64[ns]', name='date', length=247, freq=None) -
values:取值。
python= demo_values=df.values array([[ 9.54, 57.85, 32.83, ..., nan, 46. , 49.6 ], [ 9.54, 58.1 , 32.99, ..., nan, 45.9 , 50.4 ], [ 9.52, 57.6 , 32.8 , ..., nan, 49.1 , 49.1 ], ..., [ nan, 137.6 , 57.8 , ..., 131.5 , 27.2 , 14.6 ], [ nan, 138.95, 58.2 , ..., 134. , 27.35, 16.05], [ nan, 138.3 , 57.9 , ..., 129.5 , 27.25, 17.65]]) -
索引布林邏輯篩選。
ex:取得索引大於2020年份的資料。
python= demo_boolean_indexing=df[df.index>'2020'] 0015 0050 0051 0052 0053 date 2020-01-02 NaN 97.65 35.45 73.30 42.70 2020-01-03 NaN 97.65 35.30 72.85 42.58 2020-01-06 NaN 96.40 35.10 72.05 42.04 2020-01-07 NaN 96.10 34.72 71.80 41.70 2020-01-08 NaN 95.65 34.69 71.25 41.61 ... ... ... ... ... ... 2021-06-25 NaN 136.95 57.85 124.30 66.30 2021-06-28 NaN 137.20 57.90 124.20 66.15 2021-06-29 NaN 137.60 57.80 124.65 66.45 2021-06-30 NaN 138.95 58.20 125.00 66.80 2021-07-01 NaN 138.30 57.90 124.35 66.205. loc:使用標籤篩選欄列。ex:選擇2020-01-03~2020-01-08中所有標地的股價。 ```python= demo_loc1=df.loc['2020-01-03':'2020-01-08']
0015 0050 0051 0052 0053 date
2020-01-03 NaN 97.65 35.30 72.85 42.58 2020-01-06 NaN 96.40 35.10 72.05 42.04 2020-01-07 NaN 96.10 34.72 71.80 41.70 2020-01-08 NaN 95.65 34.69 71.25 41.61ex:選擇0050&1101&2330的股價,以下兩種方法等價。 ```python= demo_loc2=df.loc[:,['0050','1101','2330']] demo_column_select=df[['0050','1101','2330']]0050 1101 2330 date 2007-04-23 57.85 29.60 68.6 2007-04-24 58.10 30.25 69.8 2007-04-25 57.60 29.65 69.3 2007-04-26 57.70 29.65 69.9 2007-04-27 57.50 30.35 69.0 ... ... ... ... 2021-06-25 136.95 51.00 591.0 2021-06-28 137.20 51.10 590.0 2021-06-29 137.60 51.20 595.0 2021-06-30 138.95 51.00 595.0 2021-07-01 138.30 50.60 593.0ex:選擇2020-01-03~2020-01-08中0050&1101&2330的股價。
6. iloc:使用標籤位置篩選欄列。0050 1101 2330 date 2020-01-03 97.65 43.95 339.5 2020-01-06 96.40 43.45 332.0 2020-01-07 96.10 43.60 329.5 2020-01-08 95.65 43.40 329.5ex:選擇第6列到第10列的資料。
0054 0055 0056 0057 0058 datepython= demo_iloc1=df.iloc[5:10] 0015 0050 0051 0052 0053 date 2007-04-30 9.37 56.90 32.07 38.10 NaN 2007-05-02 9.50 57.55 32.02 38.49 NaN 2007-05-03 9.41 58.20 31.75 38.80 NaN 2007-05-04 9.59 59.20 32.41 39.23 NaN 2007-05-07 9.60 59.55 32.60 39.44 NaNpython= demo_iloc3=df.iloc[5:10,5:10]ex:選擇第6列到第10列的資料&選擇df表中第6檔到第10檔標地資料。0054 0055 0056 0057 0058 date 2007-04-23 NaN NaN NaN NaN NaN 2007-04-24 NaN NaN NaN NaN NaN 2007-04-25 NaN NaN NaN NaN NaN 2007-04-26 NaN NaN NaN NaN NaN 2007-04-27 NaN NaN NaN NaN NaN ... ... ... ... ... ... 2021-06-25 31.84 21.25 34.74 94.05 NaN 2021-06-28 31.84 21.29 35.10 94.05 NaN 2021-06-29 31.80 21.20 34.80 94.70 NaN 2021-06-30 31.90 21.26 35.00 95.45 NaN 2021-07-01 31.56 21.24 35.00 94.95 NaN
2007-04-30 NaN NaN NaN NaN NaN 2007-05-02 NaN NaN NaN NaN NaN 2007-05-03 NaN NaN NaN NaN NaN 2007-05-04 NaN NaN NaN NaN NaN 2007-05-07 NaN NaN NaN NaN NaN7. [**nlargest & nsmallest**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.nlargest.html): 1. nlargest:取前n大,ex:取近一日股價前n高的標地。python= demo_nlargest=df.iloc[-1].nlargest(10) 6415 3710.0 3008 3105.0 5274 2115.0 8454 1900.0 4966 1380.0 5269 1375.0 6409 1340.0 3529 1310.0 1590 1100.0 6669 976.0 Name: 2021-07-01 00:00:00, dtype: float64 ``` -
nsmallest:取前n大,ex:取近一日股價前n低的標地。
python= demo_nsmallest=df.iloc[-1].nsmallest(10) 8101 2.61 5701 2.85 02001R 2.88 3095 2.96 2443 2.99 6289 2.99 9188 3.09 9110 3.12 2364 3.22 6225 3.40 Name: 2021-07-01 00:00:00, dtype: float64
顯示控制
pandas預防資源消耗,預設顯示列數為10(頭尾各五列),中間資料以‘...’帶過,若想要調整顯示數量來檢視資料,可作以下控制。
Hint: 要注意的是此影響為全域,接下來的顯示數都會被影響。
-
列數全展開:
python= pd.set_option("display.max_rows", None) -
欄數全展開:
python= pd.set_option("display.max_columns", None) -
最多顯示20列:
python= pd.set_option("display.max_rows", 20) -
最多顯示20欄:
python= pd.set_option("display.max_columns", 20) -
還原顯示數預設初始值:
python= pd.reset_option("^display")
資料運算
sum:
加總,axis=0為整欄加總,axis=1為整列加總。
ex:計算每日股價大於100的標地數量
python=
產生股價大於100元的布林dataframe,若大於100則顯示True(計算時視為1),若不大於100則顯示False(計算時視為0)
price_up_10=df>100
demo_sum=price_up_10.sum(axis=1)
date
2007-04-23 70
2007-04-24 72
2007-04-25 70
2007-04-26 71
2007-04-27 71
...
2021-06-25 282
2021-06-28 285
2021-06-29 283
2021-06-30 283
2021-07-01 280
Length: 3503, dtype: int64
demo_mean=df.mean()
0015 7.697360
0050 67.783269
0051 29.989126
0052 45.283546
0053 29.846568
...
9951 84.396078
9955 30.770911
9958 29.483578
9960 24.562452
9962 12.956349
Length: 2269, dtype: float64
std:標準差,常用於計算乖離率。python=
demo_std=df.std()
9951 54.171955 9955 21.267716 9958 33.751259 9960 8.755944 9962 6.390186 Length: 2269, dtype: float64
[**max & min**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.max.html):
max:最大值。
```python=
demo_max=df.max()
0015 12.40
0050 143.00
0051 58.20
0052 136.45
0053 68.80
...
9951 220.00
9955 140.50
9958 141.50
9960 61.10
9962 50.40
Length: 2269, dtype: float64
9951 0.00 9955 10.90 9958 5.10 9960 0.00 9962 4.95 Length: 2269, dtype: float64
[**cumsum & cumprod**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.cumsum.html):
cumsum:累加。
ex:累積漲多少元。
```python=
demo_diff=df.diff()
demo_cumsum=demo_diff.cumsum()
0015 0050 0051 0052 0053
date
2007-04-23 NaN NaN NaN NaN NaN
2007-04-24 0.00 0.25 0.16 0.25 NaN
2007-04-25 -0.02 -0.25 -0.03 0.19 NaN
2007-04-26 0.05 -0.15 -0.03 0.20 NaN
2007-04-27 0.01 -0.35 -0.11 0.00 NaN
... ... ... ... ... ...
2021-06-25 NaN 79.10 25.57 86.56 37.18
2021-06-28 NaN 79.35 25.62 86.46 37.03
2021-06-29 NaN 79.75 25.52 86.91 37.33
2021-06-30 NaN 81.10 25.92 87.26 37.68
2021-07-01 NaN 80.45 25.62 86.61 37.08
ex:常用於計算累積報酬率。
python=
demo_pct_change=df.pct_change()+1
demo_cumprod=demo_pct_change.cumprod()
0015 0050 0051 0052 0053
date
2007-04-23 NaN NaN NaN NaN NaN
2007-04-24 1.000000 1.004322 1.004874 1.006510 NaN
2007-04-25 0.997904 0.995678 0.999086 1.004948 NaN
2007-04-26 1.005241 0.997407 0.999086 1.005208 NaN
2007-04-27 1.001048 0.993950 0.996649 1.000000 NaN
... ... ... ... ... ...
2021-06-25 0.966457 2.367329 1.762108 3.236979 2.207057
2021-06-28 0.966457 2.371651 1.763631 3.234375 2.202064
2021-06-29 0.966457 2.378565 1.760585 3.246094 2.212051
2021-06-30 0.966457 2.401901 1.772769 3.255208 2.223702
2021-07-01 0.966457 2.390666 1.763631 3.238281 2.203728
python=
demo_cummin=df.cummin()
[**cummax & cummin**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.cummax.html):
cummax:累積最大值,常用於計算drawdown、創新高。
```python=
demo_cummax=df.cummax()
0015 0050 0051 0052 0053
date
2007-04-23 9.54 57.85 32.83 38.40 NaN
2007-04-24 9.54 58.10 32.99 38.65 NaN
2007-04-25 9.54 58.10 32.99 38.65 NaN
2007-04-26 9.59 58.10 32.99 38.65 NaN
2007-04-27 9.59 58.10 32.99 38.65 NaN
... ... ... ... ... ...
2021-06-25 NaN 143.00 57.85 136.45 68.8
2021-06-28 NaN 143.00 57.90 136.45 68.8
2021-06-29 NaN 143.00 57.90 136.45 68.8
2021-06-30 NaN 143.00 58.20 136.45 68.8
2021-07-01 NaN 143.00 58.20 136.45 68.8
0015 0050 0051 0052 0053
date
2007-04-23 9.54 57.85 32.83 38.40 NaN
2007-04-24 9.54 57.85 32.83 38.40 NaN
2007-04-25 9.52 57.60 32.80 38.40 NaN
2007-04-26 9.52 57.60 32.80 38.40 NaN
2007-04-27 9.52 57.50 32.72 38.40 NaN
... ... ... ... ... ...
2021-06-25 NaN 29.50 13.40 17.02 11.85
2021-06-28 NaN 29.50 13.40 17.02 11.85
2021-06-29 NaN 29.50 13.40 17.02 11.85
2021-06-30 NaN 29.50 13.40 17.02 11.85
2021-07-01 NaN 29.50 13.40 17.02 11.85
[**quantile**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.quantile.html):
計算第c百分位數數值,常用於取標的數前c%強標地。
```python=
demo_quantile=df.iloc[-1].quantile(0.9)
corr: 計算相關性。 ```python= demo_corr=df.iloc[:,:5].corr()
0015 0050 0051 0052 0053 0015 1.000000 0.892513 0.922749 0.926133 0.823550 0050 0.892513 1.000000 0.852582 0.968580 0.989484 0051 0.922749 0.852582 1.000000 0.851140 0.870181 0052 0.926133 0.968580 0.851140 1.000000 0.983993 0053 0.823550 0.989484 0.870181 0.983993 1.000000
[**describe**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.describe.html):
計算統計資料。
```python=
demo_describe=df.describe()
0015 0050 0051 0052 0053
count 1640.000000 3503.000000 3500.000000 3395.000000 3435.000000
mean 7.697360 67.783269 29.989126 45.283546 29.846568
std 1.482317 19.781026 6.076147 20.926838 9.881821
min 4.150000 29.500000 13.400000 17.020000 11.850000
25% 7.090000 54.850000 26.497500 33.440000 23.880000
50% 7.490000 62.900000 29.440000 38.770000 27.100000
75% 8.300000 78.250000 32.252500 50.100000 33.825000
max 12.400000 143.000000 58.200000 136.450000 68.800000
移動窗格作業
shift: 資料移動,常用於前後期數值增減比較、年增率計算。
ex:收盤價向下平移一列,第一列會變NaN。 ```python= demo_shift1=df.shift()
0015 0050 0051 0052 0053 date2007-04-23 NaN NaN NaN NaN NaN 2007-04-24 9.54 57.85 32.83 38.40 NaN 2007-04-25 9.54 58.10 32.99 38.65 NaN 2007-04-26 9.52 57.60 32.80 38.59 NaN 2007-04-27 9.59 57.70 32.80 38.60 NaN ... ... ... ... ... ... 2021-06-25 NaN 136.70 57.60 124.70 65.75 2021-06-28 NaN 136.95 57.85 124.30 66.30 2021-06-29 NaN 137.20 57.90 124.20 66.15 2021-06-30 NaN 137.60 57.80 124.65 66.45 2021-07-01 NaN 138.95 58.20 125.00 66.80
0015 0050 0051 0052 0053
date
2007-04-23 9.54 58.10 32.99 38.65 NaN
2007-04-24 9.52 57.60 32.80 38.59 NaN
2007-04-25 9.59 57.70 32.80 38.60 NaN
2007-04-26 9.55 57.50 32.72 38.40 NaN
2007-04-27 9.37 56.90 32.07 38.10 NaN
... ... ... ... ... ...
2021-06-25 NaN 137.20 57.90 124.20 66.15
2021-06-28 NaN 137.60 57.80 124.65 66.45
2021-06-29 NaN 138.95 58.20 125.00 66.80
2021-06-30 NaN 138.30 57.90 124.35 66.20
2021-07-01 NaN NaN NaN NaN NaN
ex:計算20日移動平均線(前n筆數資料未滿10日取na,未滿20日以n日計算)。 ```python= demo_rolling=df.rolling(20,min_periods=10).mean()
0015 0050 0051 0052 0053
date
2007-04-23 NaN NaN NaN NaN NaN
2007-04-24 NaN NaN NaN NaN NaN
2007-04-25 NaN NaN NaN NaN NaN
2007-04-26 NaN NaN NaN NaN NaN
2007-04-27 NaN NaN NaN NaN NaN
... ... ... ... ... ...
2021-06-25 NaN 137.0975 55.6150 124.5325 65.8150
2021-06-28 NaN 137.1675 55.8250 124.5675 65.8725
2021-06-29 NaN 137.1925 56.0050 124.5475 65.8950
2021-06-30 NaN 137.2550 56.1575 124.5425 65.9225
2021-07-01 NaN 137.2850 56.2975 124.5550 65.9500
[**diff**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.diff.html):
列數相減。
ex:取每日漲跌價。
```python=
demo_diff=df.diff()
0015 0050 0051 0052 0053
date
2007-04-23 NaN NaN NaN NaN NaN
2007-04-24 0.00 0.25 0.16 0.25 NaN
2007-04-25 -0.02 -0.50 -0.19 -0.06 NaN
2007-04-26 0.07 0.10 0.00 0.01 NaN
2007-04-27 -0.04 -0.20 -0.08 -0.20 NaN
... ... ... ... ... ...
2021-06-25 NaN 0.25 0.25 -0.40 0.55
2021-06-28 NaN 0.25 0.05 -0.10 -0.15
2021-06-29 NaN 0.40 -0.10 0.45 0.30
2021-06-30 NaN 1.35 0.40 0.35 0.35
2021-07-01 NaN -0.65 -0.30 -0.65 -0.60
pct_change: 列數相除。
ex:取每日漲跌幅。 ```python= demo_pct_change=df.pct_change()
0015 0050 0051 0052 0053 date2007-04-23 NaN NaN NaN NaN NaN 2007-04-24 0.000000 0.004322 0.004874 0.006510 NaN 2007-04-25 -0.002096 -0.008606 -0.005759 -0.001552 NaN 2007-04-26 0.007353 0.001736 0.000000 0.000259 NaN 2007-04-27 -0.004171 -0.003466 -0.002439 -0.005181 NaN ... ... ... ... ... ... 2021-06-25 0.000000 0.001829 0.004340 -0.003208 0.008365 2021-06-28 0.000000 0.001825 0.000864 -0.000805 -0.002262 2021-06-29 0.000000 0.002915 -0.001727 0.003623 0.004535 2021-06-30 0.000000 0.009811 0.006920 0.002808 0.005267 2021-07-01 0.000000 -0.004678 -0.005155 -0.005200 -0.008982
### [視覺化](https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html)
乖離率線圖:
```python=
df=data.get('price:收盤價').iloc[-400:]['2330']
mean_20=df.rolling(20).mean()
std_value=df.rolling(20).std()
up=mean_20+std_value*2
down=mean_20-std_value*2
up.plot(label='up',legend=True)
down.plot(label='down',legend=True)
mean_20.plot(label='ma_20',legend=True)
df.plot(title='bias plot',label='close',legend=True,grid=True,figsize=(20, 8))

相關性熱力圖: ```python= df=data.get('price:收盤價') check_list=['1101','1102','2330','2454','6263','9939'] demo_corr=df.iloc[-600:][check_list].corr()
demo_corr.style.background_gradient(cmap ='viridis')\ .set_properties(**{'font-size': '20px'})
from finlab import data df = data.get('price:收盤價')限定範圍
df = df[(df.index > '2015') & (df.index < '2019')]
cond1 = df > df.rolling(5).mean() cond2 = df > df.rolling(10,min_periods=5).mean() cond3 = df > df.rolling(20,min_periods=10).mean() cond4 = df > df.rolling(60,min_periods=40).mean()
position = (df * (cond1 & cond2 & cond3 & cond4)) position = position[position > 0] position = position.is_largest(10)
from finlab import data df = data.get('price:收盤價') mean_20 = df.rolling(20).mean() std_value = df.rolling(20).std()up = mean_20 + std_value*2
收盤價剛站上布林通道上緣
cond1 = (df > up) & (df.shift() < up) cond2 = (df > 5) & (df < 200) position = (cond1 & cond2) position = position[position > 0] position = position.is_smallest(20) ```